请注意,本文编写于 99 天前,最后修改于 54 天前,其中某些信息可能已经过时。
目录
D4RT
- https://d4rt-paper.github.io/
- 一句话总结: 用一个Encoder得到视频的
Representation, 再用轻量化的Decoder查询对应像素的3d位置,实现3维重建。
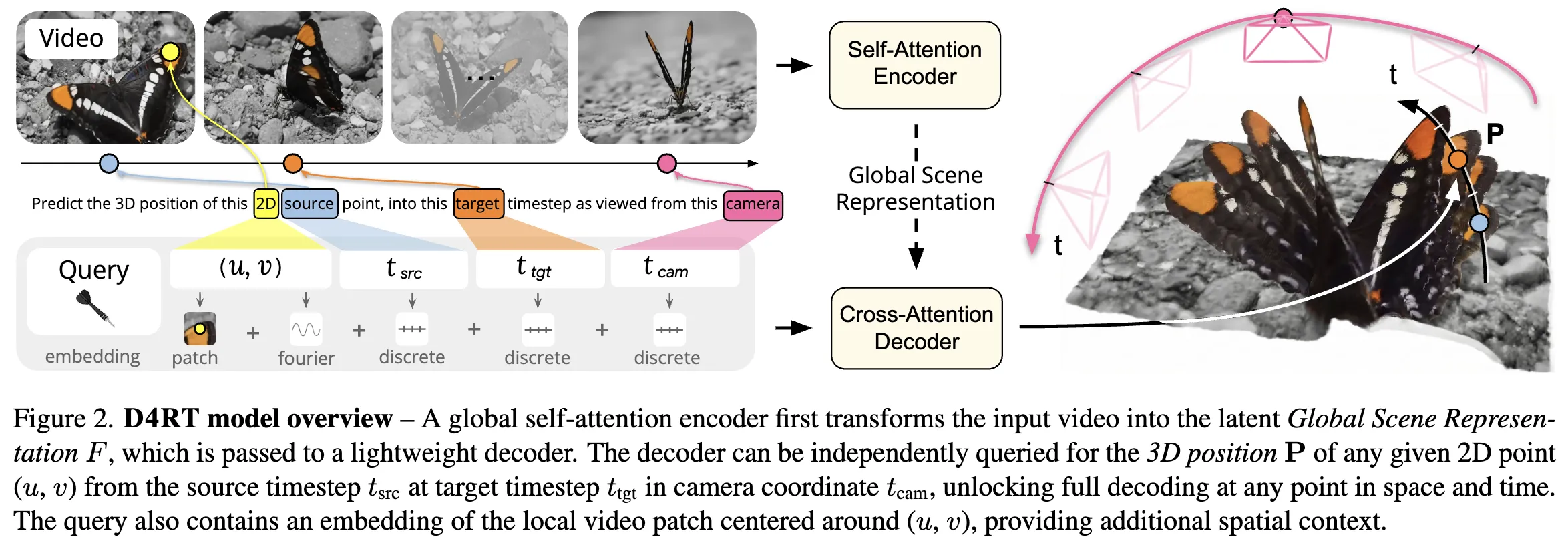
- 训练形式:
- Encoder得到
Global Scene RepresentationF - Decoder的Query使用,对F进行查询
- 代表在时刻的图像的像素
- 代表希望查询这个像素的点在时刻在相机坐标系下的点
- 好处: 监督信号的提供较为容易,推理时可以平行推理
- Encoder得到
VGGT
- https://arxiv.org/abs/2503.11651
- 一句话总结: 在加入
Camera Token后用交替注意力得到表示,用不同的head解码Camera Ex/Intrinics/point map/depth map..
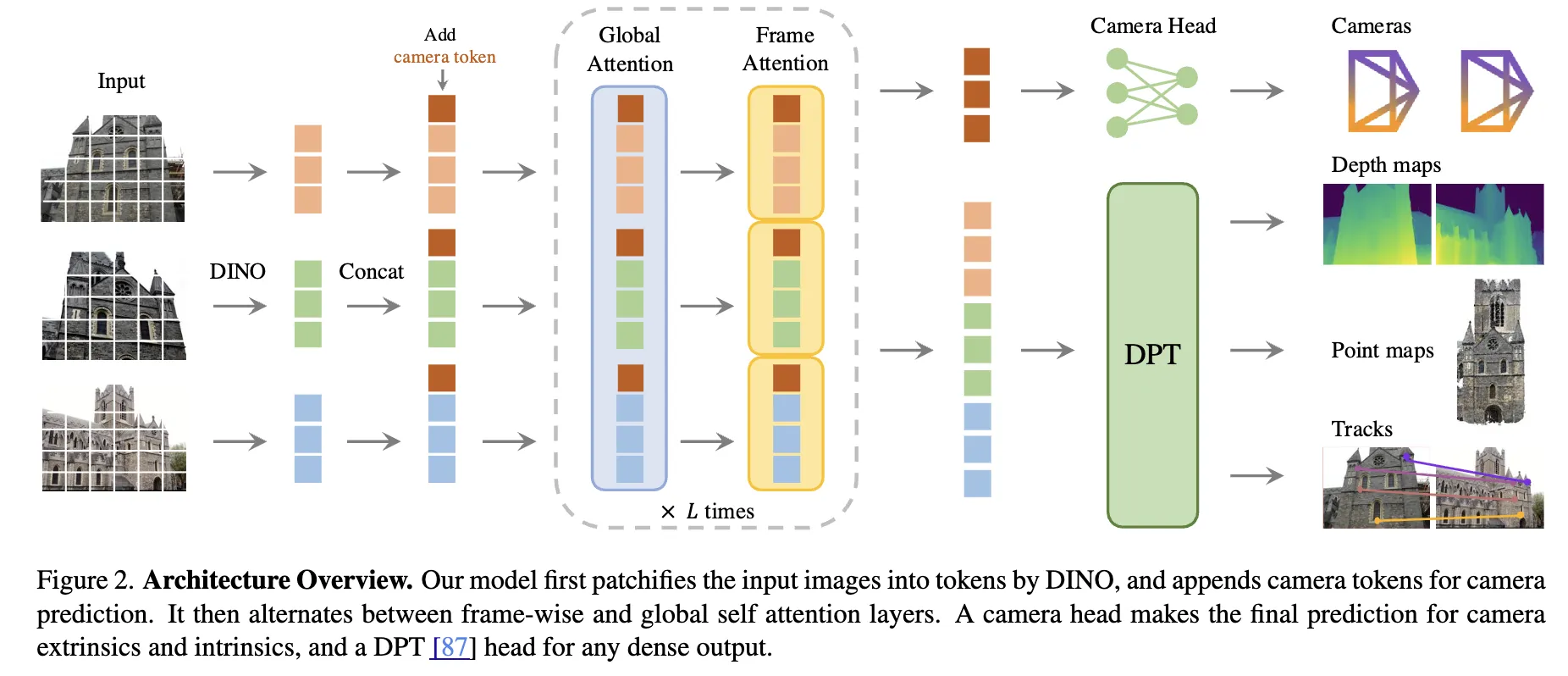
- 训练形式:
- Camera/Depth maps/Point maps都是稠密的,即一次forward全部算出来
- Point Tracking得到的是feature,再用下游方法进行追踪。
目录