强化学习基本组件
- Actor 你的策略 (一般来说你只可以控制这个)
- Environment 环境
- Reward Function 奖励函数
Policy Gradient 学习Actor
- 策略Policy一般用π表示, 用πθ来表示参数为θ的策略
- 策略的输入通常是对环境的一个观察,输出是动作的概率分布
- 我们可以这样建模一次完整的轨迹Trajectory(也许是你玩游戏的一次通关过程)
- si 第i次的环境状态
- ai 第i次针对si采取的动作
- τ={s1,a1,s2,a2,...}就建模出了一个轨迹
- pθ(τ)=p(s1)pθ(a1∣s1)p(s2∣s1,a1)pθ(a2∣s2)p(s3∣s2,a2)⋯=p(s1)∏t=1Tpθ(at∣st)p(st+1∣st,at)
- 在轨迹的中间可能会有Reward, 我们将这条轨迹上的所有Reward相加就是这条轨迹的总Reward, 称为R(τ)
- 很显然,我们想优化参数θ下的所有轨迹的期望Reward, Rθ=∑τR(τ)pθ(τ)=Eτ∼pθ(τ)[R(τ)]
- 如果我们对Rθ求梯度
∇Rθ=τ∑R(τ)∇pθ(τ)=τ∑R(τ)pθ(τ)pθ(τ)∇pθ(τ)
=τ∑R(τ)pθ(τ)∇logpθ(τ)
=Eτ∼pθ(τ)[R(τ)∇logpθ(τ)]≈N1n=1∑NR(τn)∇logpθ(τn)
=N1n=1∑Nt=1∑TnR(τn)∇logpθ(atn∣stn)
- 从而通过log的求导性质,我们将一个求和的期望变成了概率分布下的和,从而可以用蒙特卡洛等方法来获取奖励,而不用每次求Reward都遍历所有轨迹
- 更新时我们就使用θ←θ+η∇Rθ更新即可
Policy Gradient的一些可能问题及解决方法
1
- 假如所有的Reward都是正的, 那根据上述式子,我们会根据梯度增大所有采样到的pθ的值。 但是,没有采样到的动作的概率就会下降,但也许没有采样到的动作更好.
- 所以我们可以对于Reward设立一个Baseline,采样到的Reward减去baseline再代入到式子中:
∇Rθ≈N1n=1∑Nt=1∑Tn(R(τn)−b)∇logpθ(atn∣stn)b≈E[R(τ)]
这里的R(τn)−b被称为优势,Advantage,用A表示
2
- 如果以轨迹为单位来分配Reward,一条轨迹上的所有动作的Reward都相同, 不利于细粒度的优化. 实际上,通常一条轨迹上的不同动作的贡献都是不同的. 我们可以采用每个动作的奖励是这个动作的所有Reward之和.
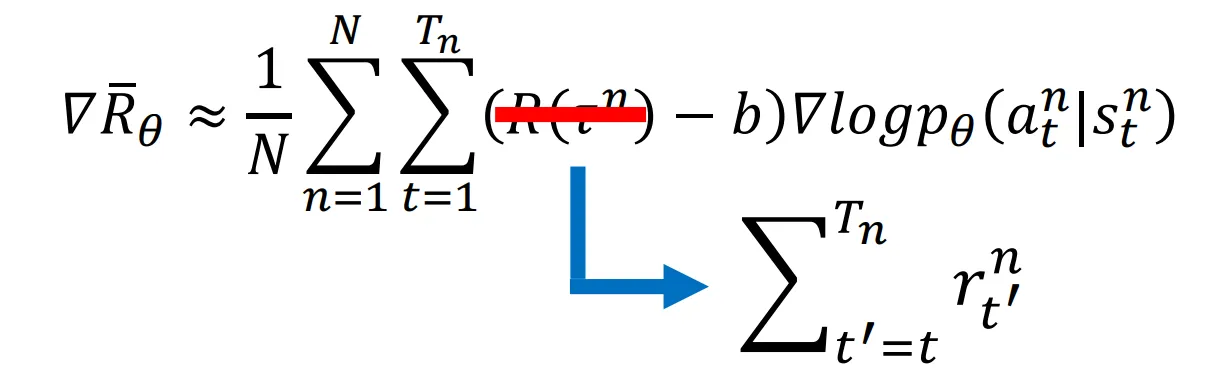
- 当然, 第一个动作可能不会对最后一个奖励产生特别大的影响, 所以也可以在求和项之前加上指数衰减的权重,但这个权重还是得看实际情况.
Off-Policy学习
- 概念: On-Policy: 和环境互动的Agent和与训练的Agent相同; Off-Policy: 和环境互动的Agent与训练的Agent不同
- 如果我们使用on-policy的话, 每次更新Agent的参数, 我们就要重新收集一遍数据。我们希望使用另一个Agent去收集数据并复用.
Ex∼p[f(x)]=∫f(x)p(x)dx=∫f(x)q(x)p(x)q(x)dx=Ex∼q[f(x)q(x)p(x)]
这样就把服从q分布的数据迁移到p分布上了
- 这样做有一个问题: 这样增大了f(x)的方差, 假如p和q分布有很大的不同,采样可能出现错误的结果
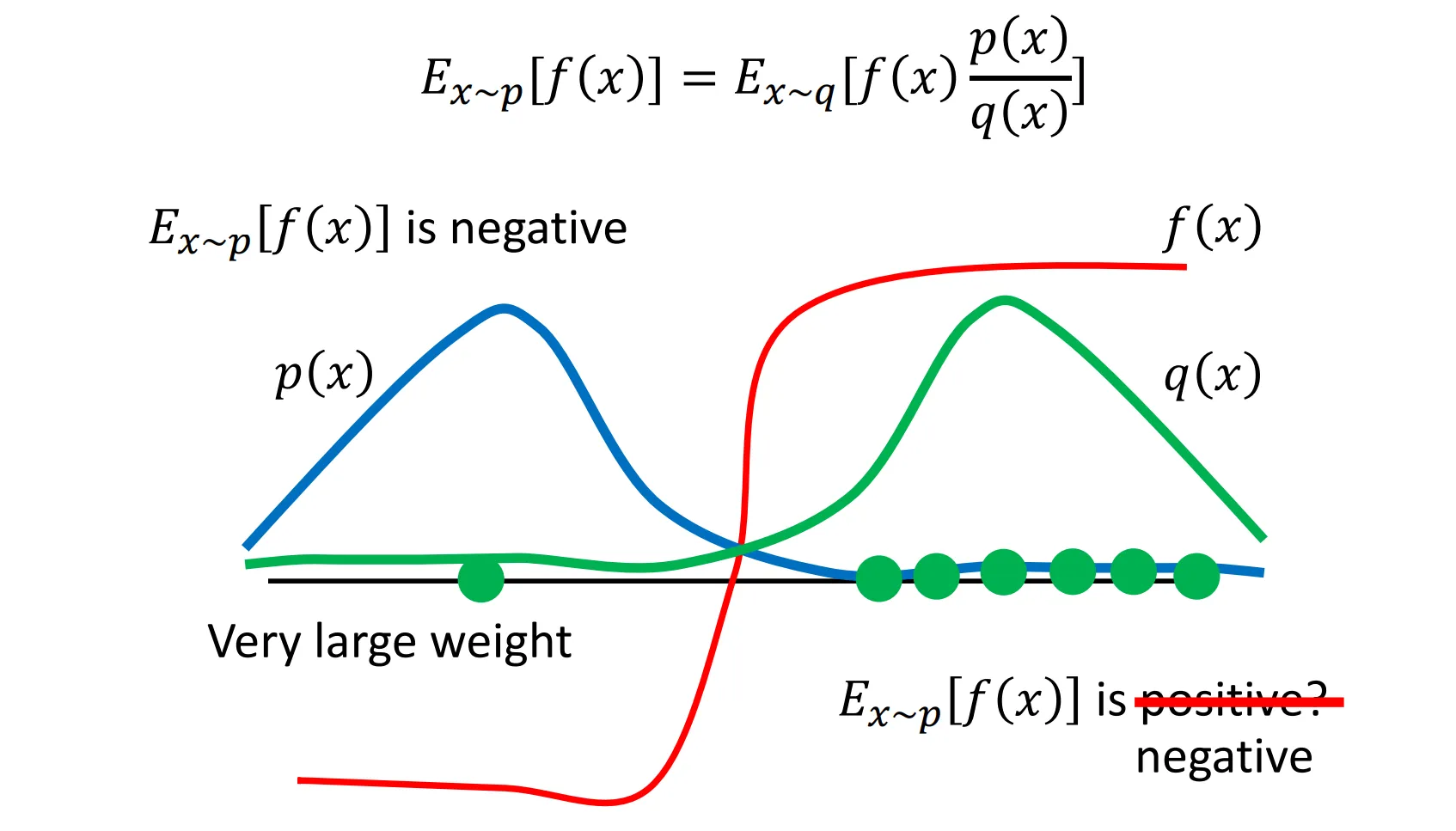 如图,本来是负的期望因为采样原因,如果根据q分布全部采样到了右边的点,可能误把期望变成正值
如图,本来是负的期望因为采样原因,如果根据q分布全部采样到了右边的点,可能误把期望变成正值
PPO/TRPO
KL散度
衡量的是“用分布Q去近似分布P时,所造成的信息损失。
DKL(P∥Q)=x∑P(x)logQ(x)P(x)
PPO
JPPOθ′(θ)=Jθ′(θ)−βKL(θ,θ′)
PPO2: 裁剪了比例,防止更新过大
LCLIP(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
TRPO
JTRPOθ′(θ)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)],KL(θ,θ′)<δ
PPO将KL散度作为惩罚项,而TRPO只计算KL散度较小部分区域.
Q-Learning
Q值估计了一个Actor在某个状态后的表现会有多好.
暂时掠过
RLHF
RLHF会有两阶段的训练: 第一阶段训练出一个奖励模型,用于奖励人类所偏好的答案; 第二阶段根据训练出的模型来后训练模型.
Reward Model
loss(θ)=−(2K)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
Post-train(最好和原数据一起训练,防止灾难性遗忘)
objective(ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain[log(πϕRL(x))]
DPO
具体原理没看懂,简单来说就是不训练Reward Model了,直接在原模型上SFT.
LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
GRPO
让大模型生成多条回,用这几条回答的平均值作为baseline, 然后和PPO差不多
JGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1i=1∑G∣oi∣1t=1∑∣oi∣{min[πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t)A^i,t,clip(πθold(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t),1−ϵ,1+ϵ)A^i,t]−βDKL[πθ∥πref]}
A^i,t=r~i=std(r)ri−mean(r)
DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1