请注意,本文编写于 396 天前,最后修改于 391 天前,其中某些信息可能已经过时。
目录
本文旨在总结在阅读多智能体协作相关论文时的感想
AutoAgents: A Framework for Automatic Agent Generation
- 论文链接: https://arxiv.org/pdf/2309.17288
- 总结: 文章提出了一种多智能体协作的框架。通过将任务分解为起草阶段和执行阶段,通过预定智能体来创造更多细化智能体并进行评估,在多轮迭代后得到答案。
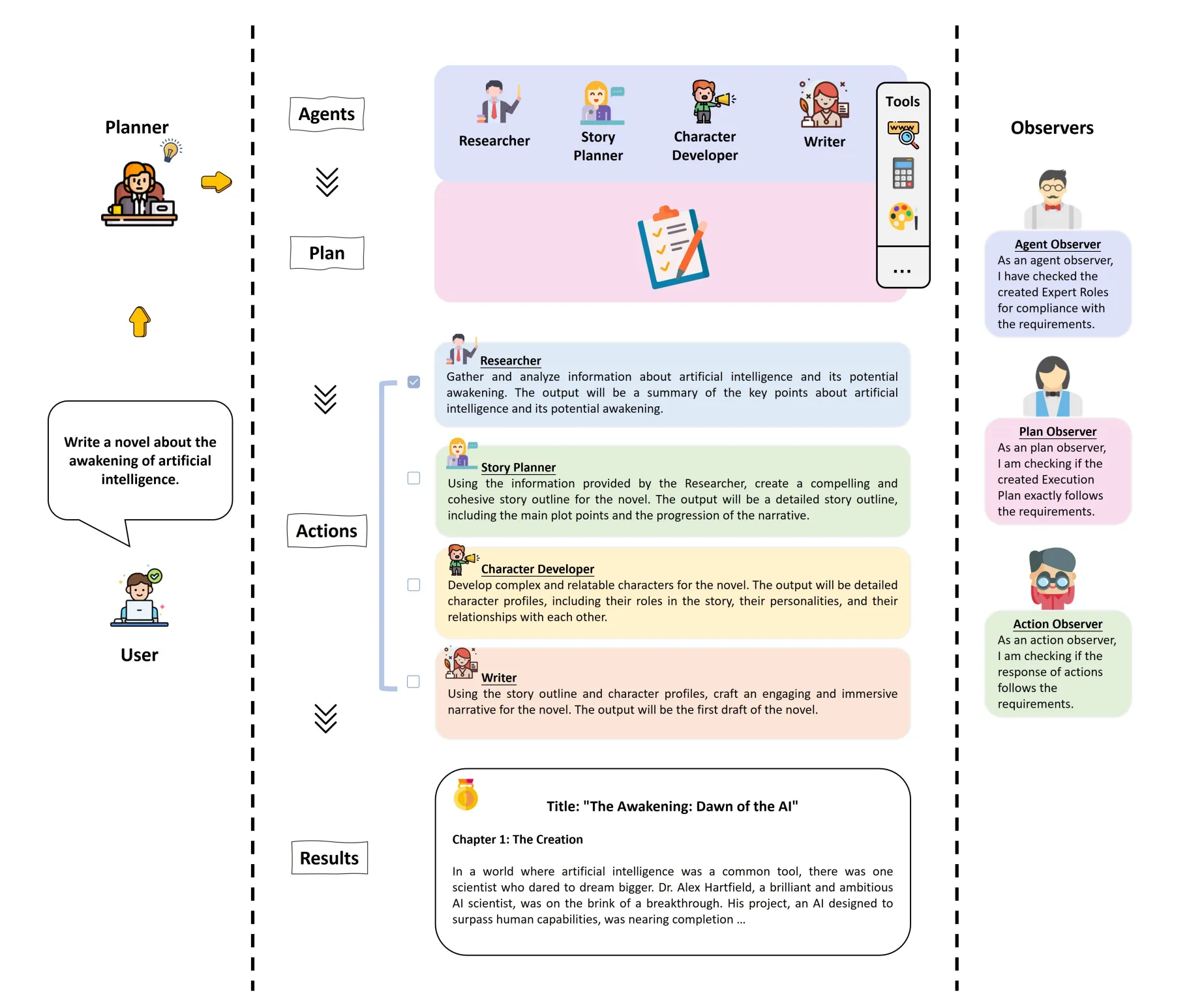
- 具体实现细节:
- 在起草阶段,
Planner会创造一个Agent队伍和计划。计划把整个任务分成几个小部分。 - 对于每个agent,
Planner需要规定A={P, D, T, S}P是Prompt指定角色, D是Description描述, T是Toolset可以使用的工具, S是suggestion对于任务执行的一些建议 Agent Observer会给出当前这个Agent是否符合任务要求,并给出反馈。Planner Observer会根据Agent列表来决定子任务是否满足要求。Planner和Agent Observer在对话至多轮后,结束。- 在执行阶段,框架会维护三种记忆:短期记忆,长期记忆、动态记忆。其中短期记忆只记忆这一轮中所有Agent的执行结果,长期记忆维护所有的执行结果,动态记忆在长期记忆的基础上添加了一些为action调整的辅助信息。
- 每一轮次对于一个子任务,
Action Observer会分配完成这个任务的Agent并为这个任务更新动态记忆。每个Agent会根据动态和短期记忆和计划,执行当前分配的任务,并把结果更新到短期记忆中。最后Action Observer会更新长期记忆。
- 在起草阶段,

- 感想:感觉有点水,需求的时间和轮次过长,结果并没有过于优势。
Blind Judgement: Agent-Based Supreme Court Modelling With GPT
- 论文链接: https://arxiv.org/pdf/2301.05327
- 总结: 文章提出了一个建模最高法院的模型。通过对9位大法官进行分开建模来模拟最高法院的判决。它可以根据判别书学习到法官的意见。
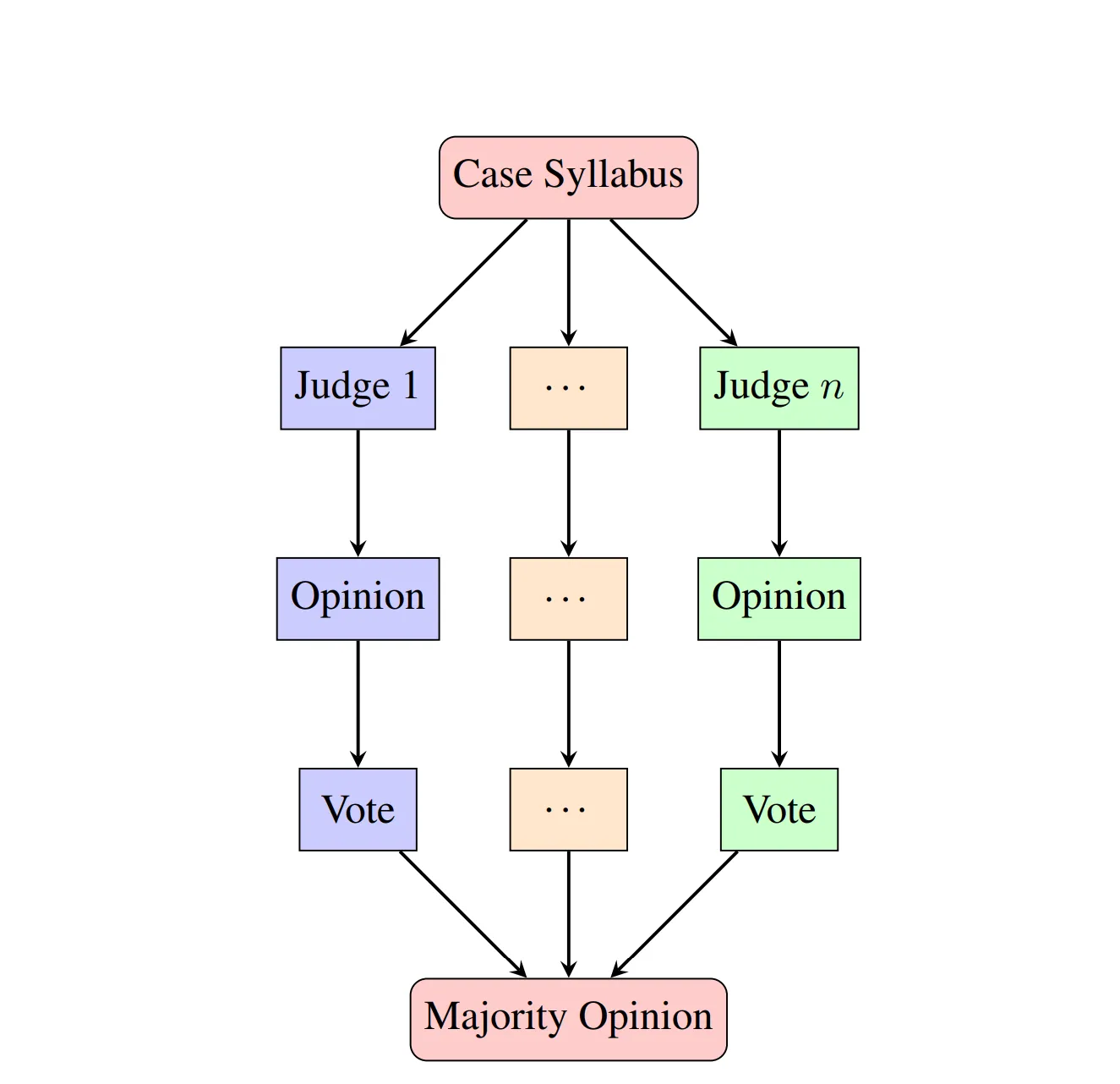
- 具体实现细节
- 作者以2003-2022的判决书为数据集。一共145MB.
- 数据集样式:{ ’issue’: ’Lorem ipsum...’, ’topic’: ’Lorem ipsum...’, ’opinion’: ’Lorem ipsum...’ ’decision’: ’Lorem ipsum...’ }用gpt-3总结的topic, 法官提出的opinion和是否赞同决议decision
- 训练 作者以gpt2为基础模型进行微调,一共训练了30个epoch。先以Robert IV的法庭形成一致意见的case为数据训练一个base model,然后根据每个法官各自对case的判罚来独立训练模型。模型最终loss为1.5, 仍有很大优化空间。
- 结果:平均60%,仅仅比随机高50%. Pearson coefficient在-0.03~0.30之间,仍有很大优化空间。
- 总结: 非常好的idea, 由于基础模型和训练数据不足等问题仍需改进。
总体总结
多智能体协作中如何共享信息是一个很重要的点。AutoAgents通过长短期记忆相结合的方式克服了上下文不足的问题,通过多个leader来把任务切分成小点并给予评估。
而Blind Judgement则是一篇很有意思的文章。与其说是多智能体,不如说是单智能体的组合,信息的共享体现在训练数据中。当然,法院的判决是一个能够非常好以自然语言体现出的方面,通过最高法院数据的注入实现了知识的表示。
目录